Introduction to Ephor Commands
Ephor allows users to create custom slash commands, providing a way to access the underlying building blocks to its AI operations. With these commands it's possible to run a pre-defined workflow or AI recipe, especially useful if the use-case is to produce a pre-structured output. The interface facilitates building complex workflows by chaining together various nodes.
Creating a New Command and Entry Point
To begin building a new custom command, simply click 'Create Command'. Each new command automatically starts with an 'ENTRY_POINT' node.
This node is a placeholder for what the user will enter with the slash command in the chat input. The text entered with the slash command is represented here by 'query', and @ mentioned documents by 'docs'.
Scoping Files with 'SCOPE_FILES'
The scope files node dynamically assess which documents to scope in or out based on the query.
To disable this behavior one can remove the {query} placeholder and hardcode a query as well.
Scoping works even without specifying {docs} in the Entry Point. Although if docs are @ mentioned in the chat input at runtime, and if the placeholder {docs} is left on the node the @ mentioning would restrict the scope to those documents. Similar to query based scoping, {docs} can be removed on the node to allow for RAG over the entire library.
Alternatively if you are building a command for a particular project, you can hardcode the name of the file from which you want to retrieve.
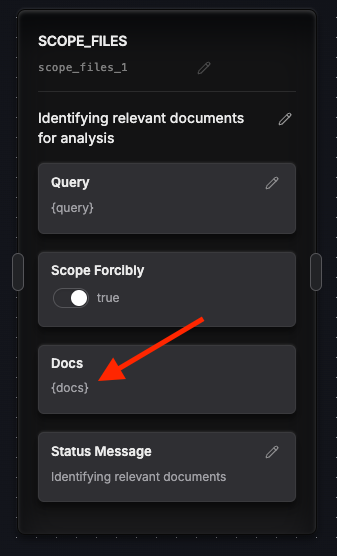
This node is necessary to be able to use the Retrieve Node as Retrieval from library only works if the 'SCOPE_FILES' node is chained together with it. This node sets up parameters for subsequent retrieval tasks, filtering the library to include only documents that match the specified query, @ mentioned or hardcoded docs in the "Docs" field.
Retrieving Information with 'RETRIEVE'
The 'RETRIEVE' node performs standard Retrieval-Augmented Generation (RAG) against the scoped library. It can use both the placeholder {query} from the chat input or a predefined hard coded one entered on the node as the value to "Query" field. It allows the configuration of parameters like 'Top K' (the number of document chunks to retrieve) - depending on the use-case you might find a higher or lower number useful. Since most chunks are the length of a short paragraph, think about how much context in the ideal case should be pulled from the library. This node is essential for fetching relevant contextual information from your knowledge base to inform the LLM's response.
Deep Retrieval with 'DEEP_RETRIEVE'
For scenarios where the entire content of specific documents is required, rather than just relevant chunks, the 'DEEP_RETRIEVE' node can be used. It takes a 'docs' input (typically from the 'ENTRY_POINT' or hard coded value of the document names in a str representation of a list "['Document 1', 'Document 2']") and retrieves the full text of those documents. This is useful for comprehensive analysis where chunking might miss crucial context.
Deep Retrieve node can be used without chaining a Scope Files before it which makes it simpler and more effective for use-cases that require context from a handful of files always needed as context for the particular command.
Forwarding Text with 'FORWARD'
The 'FORWARD' node is a simple yet powerful tool for passing specific text strings through your workflow. It takes an 'input' field where you can define any static or dynamically constructed text. This text can then be used by downstream nodes, for instance, to build dynamic prompts for LLMs or to pass predefined system messages consistently throughout a complex workflow.
Leveraging the 'AGENT' Node for Complex Interactions
The 'AGENT' node provides an agentic mode for your workflow, allowing for more complex, multi-turn interactions and reflection. It can utilize various available tools (like search or other MCP servers) to achieve a task. Unlike a single LLM query, the agent attempts to reason and refine its approach based on tool outputs, offering a more robust and adaptable solution.
Processing Lists with 'LISTIFY' and 'FOR_EACH'
For handling multiple items or iterating over data, Ephor provides the 'LISTIFY' and 'FOR_EACH' nodes. 'LISTIFY' converts an input (e.g., a body of text containing categories or an array of values) into a structured list. The 'FOR_EACH' node then allows you to loop over this list, executing a sub-workflow for each element. This enables recursive operations and processing of multiple files or data points in parallel, significantly enhancing automation capabilities.
Connecting to MCP Servers (Ephor Bus)
The Ephor Bus feature enables seamless integration with various Multi-Component Pipeline (MCP) servers, expanding the tool's capabilities. Users can add new MCP servers by providing a name and a server endpoint URL. Once connected, Ephor parses the server to identify available tools, such as Google Drive, Sheets, GitHub, web search, memory tools, and more. These tools can then be incorporated into workflows, allowing for advanced operations like data storage, retrieval, and external API calls.
Munawar Shah
Comments